-
Lavinia Baumstark authoredLavinia Baumstark authored

Start running REMIND with default settings
Felix Schreyer (felix.schreyeru@pik-potsdam.de), Lavinia Baumstark (baumstark@pik-potsdam.de) 30 April, 2019
- 1. Your first run
- 2. What happens during a REMIND run?
- 3. What happens once you start REMIND on the Cluster?
- Your first run ==================
This section will explain how you start your first run in REMIND.
Default Configurations (config/default.cfg)
The default.cfg file is divided into four parts: MODULES, SWITCHES, FLAGS, and Explanations of Switches and Flags.
a. The first part, MODULES, contains the various modules used in REMIND and various realisations therein. Various realisations within the particular module differ from each other in their features, for e.g., bounds, parametric values, different policy cases etc. Depending on the module, you see set which one to use as default (# def), and which one you can change for your current run
cfg$gms$<module nameb. The SWITCHES and FLAGS section are various settings to control, for e.g., how many iterations to run, which technologies to run, which SSP to use, start and end year of model run etc. See the fourth section, explanations of switches and flags, to know more.
Configuration with scenario_config.csv
The folder config in your REMIND folder contains a number of csv files that start with scenario_config. Those files are used to start a set of runs each with different configurations. In your REMIND folder on the Cluster, open config/scenario_config.csv in Excel. The scenario_config files have ; as their delimiter. In Excel, you might need to select the first column, choose Data and Text to Columns and set the right delimiter ; to see the csv-file spread over the columns.
In the config file, each line represents a different run. The title column labels the runs. The more runs you will have, the more it will be important that you label them in a way such that you easily remember the specific settings you chose for this run. The start column lets you choose whether or not you would like to start this run once you submit this config file to the modeling routine. It often makes sense to keep some runs in the csv file to remember their configurations for the next time although you do not want to run them now and therefore swtich them off. You do this by setting start to 0. The rest of the columns are the configurations that you can choose for the specific runs. You will see different config files with a different number of columns. If a specific setting is not specified in the config file, it takes a default value from the file config/default.cfg. Let us not worry too much about the many configurations you can do here. We will focus on this another time. We will start just one run:
Set the start value of BAU_Nash to 1 and all other runs to 0.
Your config file should look like this:

Example for a scenario_config of REMIND
Save the config file as a csv file with ; as delimiter. You can check that, for example, by opening the csv in a text editor. If the delimiter is not ;, change it in Windows under Control Panel -> Region -> Additional Settings -> List separator.
To finally start REMIND with this config file, you need to run the R-script start_bundle.R on the cluster on this config file. For this:
Starting the Run
Open a Putty session on the Cluster. Go to your REMIND folder (i.e. you have "config", "core", and "modules" as subfolders) and type directly:
Rscript start.RAlso, on Windows, you can double-click the start.cmd file. NOTE: In order to use those scripts on local machines, you have to have R installed on your machine. Don't forget to update the R libraries from time to time (explained in the Wiki page above, you need to do it only on local machines, on the cluster it happens automatically)
For starting one single or a bundle of runs via scenario_config.csv you use the file start_bundle.R and type:
nohup Rscript start_bundle.R config/scenario_config.csv &Now, keep your fingers crossed that everything works as it should.The process of your job submission is documented in the file nohup.out that you created with the nohup command. After a couple of minutes, you should see something like Submitted Batch Job ... in the nohup.out file. This means that your run has been started. To see how far your run is or whether it was stopped due to some problems, go to the Output folder and type
rsinto the Putty console. For more commands to manage your runs, type piaminfo.
NOTE: A few words on the scripts that we currently use to start runs. The scripts containing the string 'start' have a double functionality:
- they create the full.gms file and compile the needed files to start a run in a subfolder of the output folder
- they submit the run to the cluster or to your GAMS system if you work locally The scripts containing the string 'submit' have only the second of the above funcionalities, that's why they are found only inside the run folders and are used directly from there.
Shortly, a message will be displayed specifying the number of job submission; the message will look similar to the following:
The job "cwsa.iplex.pik-potsdam.de.65539" has been submitted.You can check if the running has been accepted by the cluster just by using the command
squeue -u yourusernamein the terminal.
- What happens during a REMIND run? =====================================
This section will give some technical introduction into what happens after you have started a run. It will not be a tutorial, but rather an explanation of the different parts in the modeling routine. The whole routine is illustrated in Figure 1. The core of the model is the optimization written in GAMS. However, there is some pre-processing of the input data and some post-processing of the output data using R scripts.
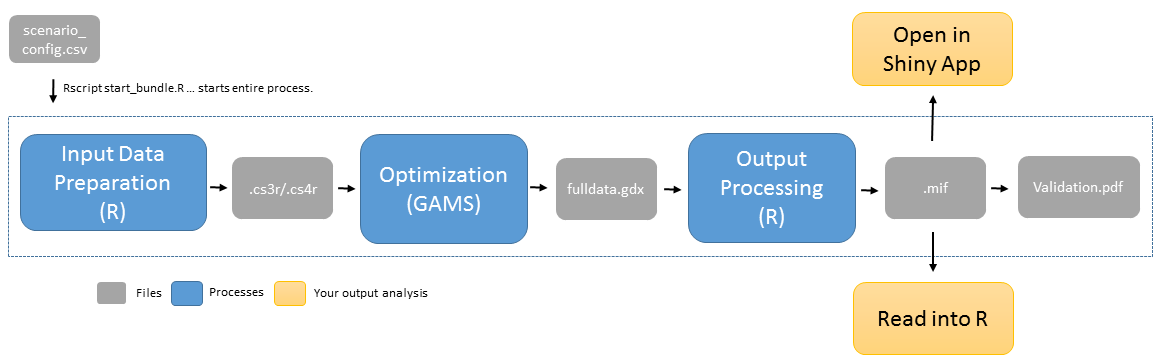
REMIND modeling routine
- What happens once you start REMIND on the Cluster? =======================================================
First, a number of R libraries like madrat, moinput and remind are loaded into your cache on the Cluster. These libraries were and are still developed at PIK. They contain the functions necessary for the input data preparation and the output processing. Let us go through each of the stages and briefly describe what happens:
a) Input Data Preparation
The optimization in REMIND requires a lot of input data. For example, the model needs to know energy production capacities per region for its initial time steps. Furthermore, it builds on GDP, population and energy demand projections that are results of other models. These kind of data are stored on the Cluster in
/p/projects/rd3mod/inputdata/sources.The data are mostly in csv files. During the input data preparation, these files are read and processed, using functions from the moinput library. Input data are available on country-level. Then, depending on the regionmapping file you chose in the config file of your run, the country-level data are aggregated into regions, e.g. to LAM (Latin America), EUR (Europe) and so on. Finally, the data are stored as .cs3r or .cs4r files in various input folders of your REMIND directory. These files are basically tables, too, that you can open with a text editor or Excel. For example, you find the input file p_histCap.cs3r in your REMIND directory under core/input. It provides the model with historically observed values of installed capacities of some technologies in the respective regions.
The regional resolution of the run is set in the config/default.cfg by
cfg$regionmapping(default setting: regionmapping <- "config/regionmappingH12.csv"). Based on the regional resolution and the input data revision
cfg$revisionthe name of the needed input data is constructed. It is checked whether those input data are already available. If not they are automatically downloaded from from /p/projects/rd3mod/inputdata/output/ and distributed.
b) Optimization
The actual REMIND is written in GAMS, a programming software to numerically solve optimization problems. The GAMS scripts are .gms files that you can find under the core (main part of the model) and the modules directories (subparts of the model). Fundamentally, we distinguish between two kinds of variables: variables (starting with v_) and parameters (starting with p_). Parameters are fix (exogenous data in economist's lingo), while variables are free within a certain range and can be adjusted to maximize the objective function of the optimization problem (endogenous variables in economist's lingo). However, there are many constraints that fix relations between the variables and parameters. Within the remaining solution space, the optimization procedure tries to find the maximum of the objective function. The output file of the optimization is the fulldata.gdx which is under output in the folder of your REMIND run. You can open it, for instance, with GAMS IDE or load it into R using the command readGDX() (see details below) . In the file, you can find, among other things, the optimal levels of the variables (variable.l) and all the predefined parameter values.
c) Output Processing
The output processing works with a number of R functions from the remind library (most of them start with report... .R). The wrapper function convGDX2MIF.R writes the most relevant output into the so-called .mif file. Again, it is a table that you can open in Excel for example. You find under output in the folder of your REMIND run as
REMIND_generic_YourRun.mifwhere YourRun is the name of the run you specified in the first column of the config file. It is important to keep in mind that between fulldata.gdx and the .mif file and number of calculations and conversions are happening which makes the variables in both files different. For output analysis, the .mif file is often more helpful, while in case you want to trace back some problem with the GAMS optimization, it can be necessary to directly look at optimal levels, marginals (values that tell you whether a variation of the variable increase or decrease the welfare level) or bounds (maximum and minimum value allowed for variable) that you all find in the fulldata.gdx created right after the optimization.